Как спарсить сайт, PhantomJS

Дисклеймер: статья старая, информация, скорее всего, устарела, используйте на свой страх и риск.
Нужно загрузить большое количество страниц с чужого сайта, но при этом обычными серверными запросами (curl и т.п.) сделать это не удается? На помощь приходит PhantomJS, браузер из консоли с управлением на JS.
Быстрый старт
Устанавливаем на centos 7:
yum -y install bzip2 fontconfig npm npm install phantomjs -g sudo ln -s /usr/lib/node_modules/phantomjs/lib/phantom/bin/phantomjs /usr/local/bin/
Закидываем в корень веб-сервера getHtmlSource.js скрипт с содержанием:
var page = require('webpage').create(), address; var system = require('system'); //Проверяем аргументы, 1 - url сайта - обязательный if (system.args.length === 0) { console.log('Usage: getHtmlSource.js <some URL>'); system.exit(); } address = system.args[1]; page.open(address, function (status) { console.log(page.content); // Выводим страницу в консоль, php заберет данные в переменную phantom.exit(); });
Далее уже на php выполняем скрипт:
$cmd = 'cd /home/bitrix/www/phantomjs && phantomjs --ignore-ssl-errors=true --ssl-protocol=any getHtmlSource.js "https://google.com/"'; $html = shell_exec($cmd); var_dump($html);
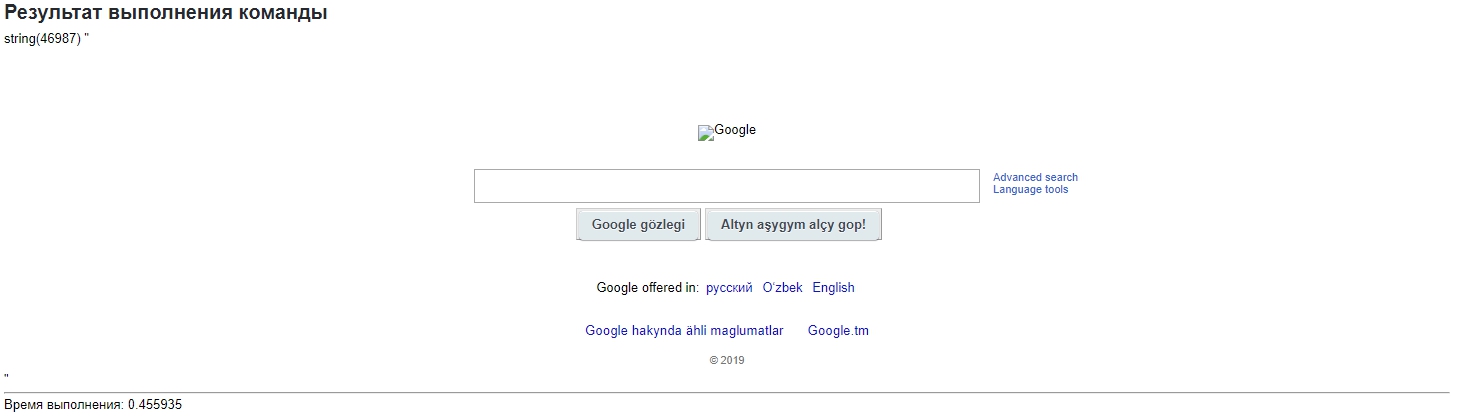
Вот Вам результат выполнения такой команды. Даже гугл отдает страницу без блокировки.
Есть вопрос или нашли ошибку? Напишите комментарий (можно без регистрации), отвечать стараюсь быстро.

{kind=link}
{kind=link}